Dual Streaming for Hardware-Accelerated Ray Tracing
PhD Thesis
University of Utah, 2019
Abstract
Hardware acceleration for ray tracing has been a topic of great interest in computer graphics. However, even with proposed custom hardware, the inherent irregularity in the memory access pattern of ray tracing has limited its performance, compared with rasterization on commercial GPUs. We provide a different approach to hardware-accelerated ray tracing, beginning with modifying the order of rendering operations, inspired by the streaming character of rasterization. Our dual streaming approach organizes the memory access of ray tracing into two predictable data streams. The predictability of these streams allows perfect prefetching and makes the memory access pattern an excellent match for the behavior of DRAM memory systems. By reformulating ray tracing as fully predictable streams of rays and of geometry we alleviate many long-standing problems of high-performance ray tracing and expose new opportunities for future research. Therefore, we also include extensive discussions of potential avenues for future research aimed at improving the performance of hardware-accelerated ray tracing using dual streaming
Description
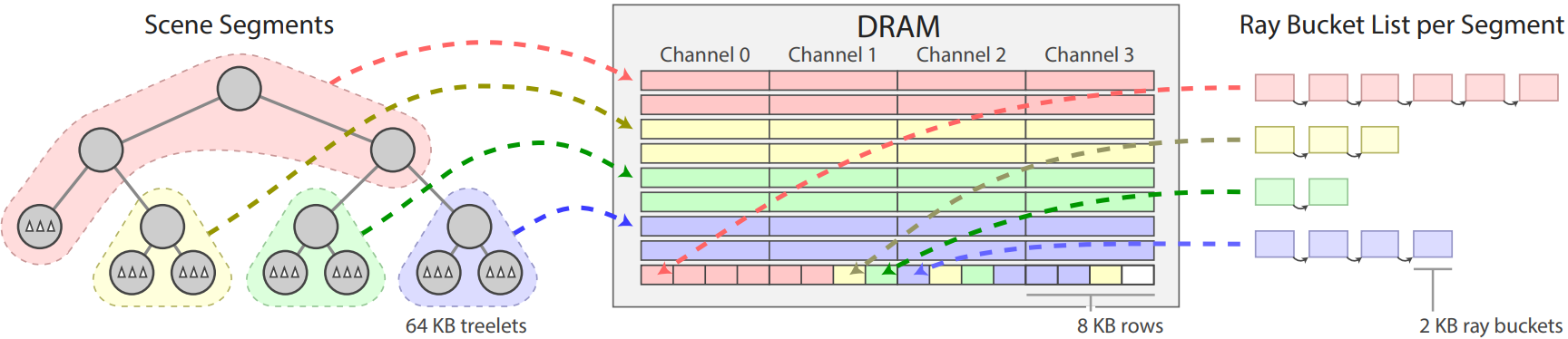
This thesis introduces the dual streaming approach for ray traversal, which reorders the traditional ray tracing algorithm to make it more suitable for hardware acceleration, considering DRAM behavior. Our dual streaming approach organizes the memory access pattern of ray tracing into two predictable and prefetch-friendly data streams: one for scene data and one for ray data. Therefore, we pose ray tracing in a fully streamed formulation, reminiscent of rasterization. The scene stream consists of the scene geometry data (including the acceleration structure) that is split into multiple scene segments. The ray stream consists of all rays in flight collected as a queue per scene segment they intersect. Our scheduler prefetches a scene segment and its corresponding ray queue from the main memory into on-chip buffers before both data are needed for traversal (i.e., perfect prefetching). Hence, the compute units no longer access the main memory directly. Rays at the same depth are traced together as a wavefront, so simulating each additional light bounce requires an additional computational pass. A predictable scene traversal order ensures that each scene segment is streamed at most once per ray wavefront. Thus, we regularize the memory traffic for scene data and reduce it to its absolute minimum.

Selection of results
We use a cycle-accurate simulator SimTRaX to evaluate our dual streaming architecture and we compare our results to STRaTA, a state-of-the-art ray tracing specific architecture. The choice of STRaTA for direct comparison is motivated by the fact that it also aims to optimize DRAM accesses (although using a traditional ray tracing paradigm) and thus we can design fair comparisons by simulating similar hardware parameters. We also provide limited comparisons against NVIDIA’s OptiX GPU ray tracer, Microsoft’s DXR ray tracer, and Intel’s Embree CPU ray tracer, running on actual hardware.
We use eight test scenes to represent a range of complexities and scene sizes. They are rendered using path tracing with five bounces, producing a highly incoherent collection of secondary rays, which is both challenging for high performance ray tracing and typical for realistic rendering. Each image is rendered at the resolution of 1024 × 1024 pixels, resulting in at most 10.5 million total rays, including both primary and secondary. We use a simple Lambertian diffuse material on all scenes, so that the results are not skewed by expensive shading operations.
A seletion of results are shown below. We compare the render times per frame, DRAM energy per frame based on hardware simulations, and the number of cache lines transferred from DRAM. See thesis document for a more in depth analysis of the proposed architecture.



BibTeX
@phdthesis{ks:phdThesis:2019,
title = {Dual Streaming for Hardware-Accelerated Ray Tracing},
author = {Konstantin {Shkurko}},
year = {2019},
school = {University of Utah}
}Acknowledgements
This work would not have been possible without the support from my advisors Erik Brunvand and Cem Yuksel; my PhD committee Rajeev Balasubramonian, Valerio Pascucci and Peter Shirley; friends and my family. Additional support was provided by the Hardware Ray Tracing group, the Graphics lab, the School of Computing and the Scientific Computing and Imaging Institute at the University of Utah. Finally, the work was supported by the National Science Foundation under Grant No. 1409129.
Thank you!